今天對我來說就是最後一天了,明天我希望能夠做一個總整理 (~發懶。今天的實測依然在極短期的股票策略預測,並延用前一篇「偏門RL實測 :: 用超簡單股票交易模擬器來訓練模型」的奇葩式訓練法,加以訓練和改善。
好孩子千萬不能學喔 ~
今天最主要想要實測怎麼樣可以調好一個RL環境的超參數,並最大化地提供最合適的Reward。 我會比較用手動調整以及透過簡單演算自動調整,看看哪個可以調的好 (然後沒有然後了...Orz
其實RL裡面有兩種策略,一種是「對環境不了解(Model-Free)」,另一種是「對環境有了解(Model-Based)」,但無論哪種, 訓練後都能夠對環境有所了解 。但我目前的訓練方式完全沒有使用到環境優勢,原因在於我並沒有把環境的狀態(state)輸入給模型中進行訓練,模型不知道我現在有多少錢、買進時的價格或甚至賣出時的價格,所以更無法精確地知道我做了這個action後所大約能得到的reward。
因為取樣關係,我只會看前n刻的資料,所以在沒有「狀態」的前提下,模型無法得知「是否要到了收盤的時間點」,所以訓練出來的模型並不會因為要收盤而賣出股票。 這也是我到目前還沒有合併好幾天的資料一起train的原因XD
那幹啥做呢?
跟前幾篇比較呀! 如果用這個方法可行的話,在正規化相同的情況下,即可證明這樣的方式更勝過我們定義好答案的學習模式XDD
我們必須要定義我們環境中的超參數。先說說我們對訓練結果的三大訴求 :
do_nothing或是都買都賣)do_nothing)而在我設計的環境中,有兩個影響loss且對立的計算
do_nothing和2.5次買、2.5次賣出現這部份實在是要細說很難... 而且我寫得真的很亂,如果不介意就去看程式碼吧XD
所以超參數是...
超參數就是「買賣數量比」和「總資產」,的權重,如果讓「總資產」主導,容易會造成模型預測「不動作」。如果讓「買賣數量比」主導,模型並不一定會往「賺錢」的方向走,這兩個都是必須的。
這邊先給一個前提,我都先將「賠錢」時的loss權重定為0.0001,所以我只要調整「買賣數量比」的權重即可。
local minimum Orz,直接奔潰啊!! 還是跟著我希望的「買賣數量比」有關的Orz最主要是因為在沒有model state的情況下,我們仍然希望環境能夠學習do_nothing是很困難的,我們很容易不小心往「學得太難賣」或是「學得一直賣」的方向走,不管了,總之先上結果吧!
比較於「比較不簡略的單股買賣模擬器 :: 面對現實吧 !」中的方法一與方法二
| - | 沒加入手續費 | 加入手續費 |
|---|---|---|
| 方法一 |  |
 |
| 方法二 |  |
 |
| 今天實作01 | 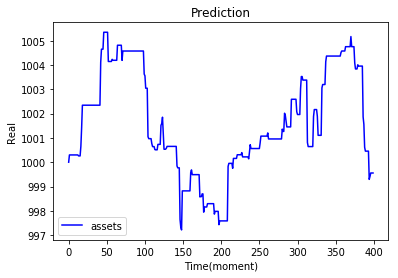 |
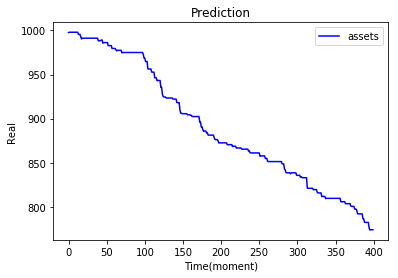 |
| 今天實作02 | 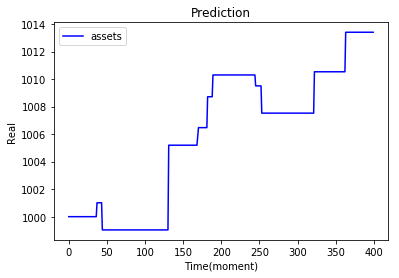 |
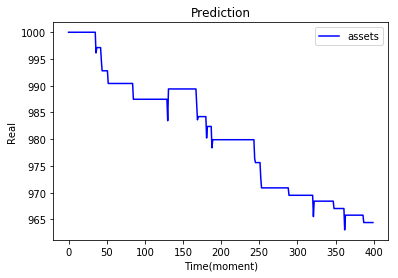 |
| 今天實作03 | 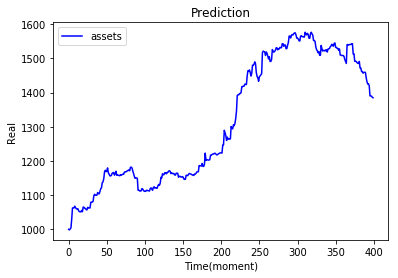 |
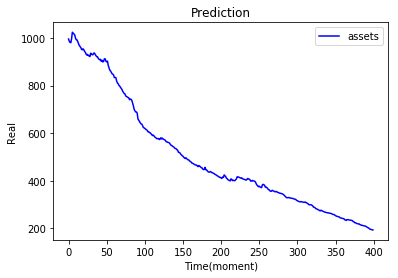 |
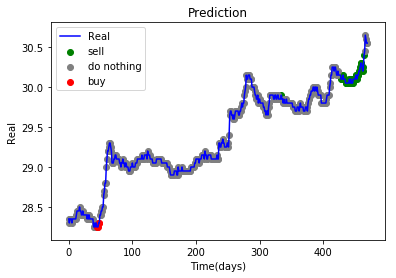
上方的實作結果都是調整參數後的輸出,可以直接透過參數改變訓練出來action比例,也可以透過修改環境使得輸出更貼近極限。
在上面的實作03應該是我調出來的最好結果... 因為在沒有模型狀態的輸入之下,也會有賣出的動作
感想來說... 要調出好的參數真的要費一番功夫,設計Reward也是很難得的經驗,只差在還沒引入環境狀態,不然可能可以訓練得更好XD 最後為了要讓它「可以賣」我真的絞盡腦汁 (抱歉...我是菜雞XD 。 這篇是股票的實作系列最終章,明天附上大整理,包括我有做的和我還沒做卻想做的(嗚嗚 時間有限Orz ,感想什麼的,明天吧 !

